Linux 内核内存管理
[toc]
越整理发现知识越多,分页机制、伙伴算法、slab等任何一块单独拿出来都有很多东西,因此本文先粗略的统揽全貌,有时间再针对每个部分,逐个深入,单独分析梳理成文章。
内存寻址的基本框架
Linux内核的映射机制分三层:页面目录:PGD, 中间目录:PMD, 页表PT。PT的表项称为PTE (Page Table Entry). PGD PMD以及PT三者都是数组。三者的关系如图所示。
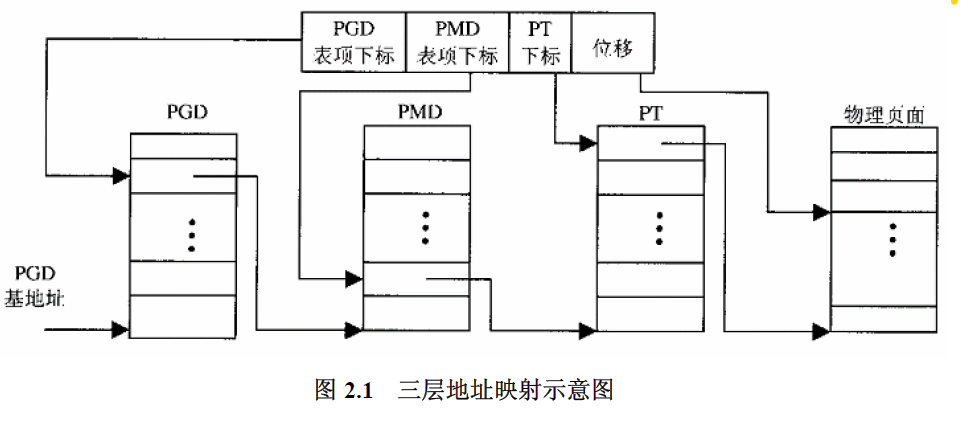
CPU给出的线性地址在逻辑上可以分为4个位段,各占若干位。分别用作在页面目录表PGD中的下标志,页中间目录表PMD中的下标,页表PT中的下标,以及物理页内的地址偏移。线性地址映射为物理地址的大致过程如下。
- CPU发出线性地址;
- 用1中线性地址的最高位段中的值,在
PGD中找到相应的表项,该表项的内容指向PMD的地址; - 用1中线性地址的第二个位段中的值,在
PMD中找到相应的表项,该表项的内容指向PT的地址; - 用1中线性地址的第三个位段中的值,在
PT中找到相应的表项,该表项是PTE,即存储物理页面的地址。 - 在4中找到的物理页中,以1中线性地址的最后一个位段的内容作为地址偏移量,找到对应的物理地址。
i386的MMU只支持两级页表,对于Pentium Pro开始Intel引入了物理地址扩充功能PAE,允许将32位的地址线扩展为36位,并在硬件上支持了三层映射。两层映射、三层映射甚至64位机器的四层映射,原理都是相似的,力图简单,先搞懂两层映射。
arch/x86/include/asm/pgtable_32_types.h中的宏CONFIG_X86_PAE在内核配置的过程中(arch/x86/Kconfig中)生成,决定是否开启PAE。
1
2
3
4
5
6
7
8
9
10
11
12
13
| /* arch/x86/include/asm/pgtable_32_types.h */
/*
* The Linux x86 paging architecture is 'compile-time dual-mode', it
* implements both the traditional 2-level x86 page tables and the
* newer 3-level PAE-mode page tables.
*/
#ifdef CONFIG_X86_PAE
# include <asm/pgtable-3level_types.h>
# define PMD_SIZE (1UL << PMD_SHIFT)
# define PMD_MASK (~(PMD_SIZE - 1))
#else
# include <asm/pgtable-2level_types.h>
#endif
|
不开启PAE时即包含<asm/pgtable-2level_types.h>头文件,即采用两级页表。
1
2
3
4
5
6
7
8
9
| /* arch/x86/include/asm/pgtable-2level_types.h */
/*
* traditional i386 two-level paging structure:
*/
#define PGDIR_SHIFT 22 /* 表示线性地址中PGD下标位段在线性地址中的起始位置,即从bit22开始到bit31共10位 */
#define PTRS_PER_PGD 1024 /* 代表每个PGD表中指针个数 */
/* arch/x86/include/asm/pgtable_32_types.h */
#define PGDIR_SIZE (1UL << PGDIR_SHIFT) /* 表示PGD中每一个表代表1x2^22的地址空间 */
|
默认状态下,32位的地址空间分为 0x00000000 - 0xBFFFFFFF 3G的用户态空间,和0xC0000000 - 0xFFFFFFFF 1G的内核态空间。下边的配置项决定内核空间的开始位置,默认是从0xC0000000开始的1G空间。
1
2
3
4
5
6
7
8
9
| /* arch/x86/Kconfig */
config PAGE_OFFSET
hex
default 0xB0000000 if VMSPLIT_3G_OPT
default 0x80000000 if VMSPLIT_2G
default 0x78000000 if VMSPLIT_2G_OPT
default 0x40000000 if VMSPLIT_1G
default 0xC0000000
depends on X86_32
|
关于PAGE_OFFSET宏的定义如下过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| /* arch/x86/include/asm/page_types.h */
#define PAGE_OFFSET ((unsigned long)__PAGE_OFFSET)
/* 其中__PAGE_OFFSET定义在 arch/x86/include/asm/page_32_types.h*/
/*
* This handles the memory map.
*
* A __PAGE_OFFSET of 0xC0000000 means that the kernel has
* a virtual address space of one gigabyte, which limits the
* amount of physical memory you can use to about 950MB.
*
* If you want more physical memory than this then see the CONFIG_HIGHMEM4G
* and CONFIG_HIGHMEM64G options in the kernel configuration.
*/
#define __PAGE_OFFSET _AC(CONFIG_PAGE_OFFSET, UL)
/* CONFIG_PAGE_OFFSET 由前边arch/x86/Kconfig中的配置项PAGE_OFFSET决定 */
|
由此原理内核定义了一套用于内核空间中简单的地址转换方式。
1
2
3
4
5
6
7
| /* arch/x86/include/asm/page.h */
#define __pa(x) __phys_addr((unsigned long)(x))
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
/*arch/x86/include/asm/page_32.h*/
#define __phys_addr_nodebug(x) ((x) - PAGE_OFFSET)
#define __phys_addr(x) __phys_addr_nodebug(x)
|
地址映射全过程
假设hello-world程序编译链接加载完的程序入口地址是0x08048568,CPU要执行此程序,首先此地址经过MMU得到对应的物理地址,将CS:EIP的地址指向该物理地址,之后CPU就可以运行此程序的代码。
首先看一下段式映射机制,即得到物理地址后CPU怎么执行。
段式映射机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| /* arch/x86/include/asm/processor.h */
extern void start_thread(struct pt_regs *regs, unsigned long new_ip,
unsigned long new_sp);
/* /arch/x86/kernel/process_32.c */
void
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
set_user_gs(regs, 0);
regs->fs = 0;
set_fs(USER_DS);
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
regs->ip = new_ip;
regs->sp = new_sp;
/*
* Free the old FP and other extended state
*/
free_thread_xstate(current);
}
EXPORT_SYMBOL_GPL(start_thread);
/* /arch/x86/include/asm/segment.h */
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS * 8)
/*(12+0)*8=96 : 60H : 0000 0000 0110 0000*/
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS * 8)
/*(12+1)*8=104 : 68H : 0000 0000 0110 1000*/
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS* 8 + 3)
/* 15*8+3=123 : 7BH : 0000 0000 0111 1011*/
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS* 8 + 3)
/* 14*8+3=115 : 73H : 0000 0000 0111 0011*/
#define GDT_ENTRY_KERNEL_BASE 12
#define GDT_ENTRY_KERNEL_CS (GDT_ENTRY_KERNEL_BASE + 0)
#define GDT_ENTRY_KERNEL_DS (GDT_ENTRY_KERNEL_BASE + 1)
#define GDT_ENTRY_DEFAULT_USER_CS 14
#define GDT_ENTRY_DEFAULT_USER_DS 15
|
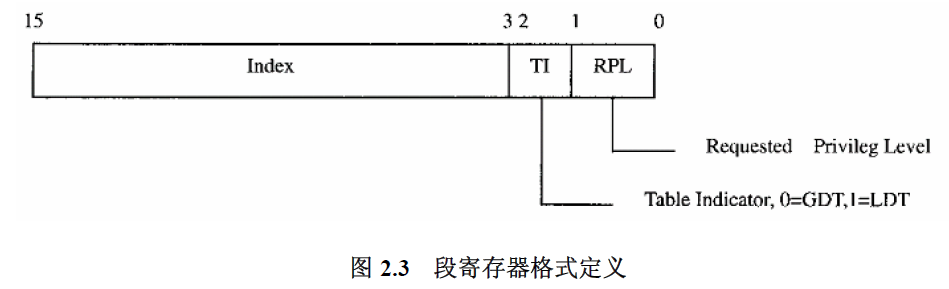
对应到段寄存器格式定义可得下边的表,即四个段全在GDT中。
| index | TI | RPL |
|---|
| __KERNEL_CS | 12 | 0 | 0 |
| __KERNEL_DS | 13 | 0 | 0 |
| __USER_DS | 15 | 0 | 3 |
| __USER_CS | 14 | 0 | 3 |
内核GDT表的映像在arch/x86/include/asm/segment.h的注释可以看出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| /*
* The layout of the per-CPU GDT under Linux:
*
* 0 - null
* 1 - reserved
* 2 - reserved
* 3 - reserved
*
* 4 - unused <==== new cacheline
* 5 - unused
*
* ------- start of TLS (Thread-Local Storage) segments:
*
* 6 - TLS segment #1 [ glibc's TLS segment ]
* 7 - TLS segment #2 [ Wine's %fs Win32 segment ]
* 8 - TLS segment #3
* 9 - reserved
* 10 - reserved
* 11 - reserved
*
* ------- start of kernel segments:
*
* 12 - kernel code segment <==== new cacheline
* 13 - kernel data segment
* 14 - default user CS
* 15 - default user DS
* 16 - TSS
* 17 - LDT
* 18 - PNPBIOS support (16->32 gate)
* 19 - PNPBIOS support
* 20 - PNPBIOS support
* 21 - PNPBIOS support
* 22 - PNPBIOS support
* 23 - APM BIOS support
* 24 - APM BIOS support
* 25 - APM BIOS support
*
* 26 - ESPFIX small SS
* 27 - per-cpu [ offset to per-cpu data area ]
* 28 - stack_canary-20 [ for stack protector ]
* 29 - unused
* 30 - unused
* 31 - TSS for double fault handler
*/
/* Constructor for a conventional segment GDT (or LDT) entry */
/* This is a macro so it can be used in initializers */
#define GDT_ENTRY(flags, base, limit) \
((((base) & 0xff000000ULL) << (56-24)) | \
(((flags) & 0x0000f0ffULL) << 40) | \
(((limit) & 0x000f0000ULL) << (48-16)) | \
(((base) & 0x00ffffffULL) << 16) | \
(((limit) & 0x0000ffffULL)))
|
关于gdt的建立过程,在内核的初始化阶段完成,搜索内核代码发现在arch/x86/kernel/cpu/common.c定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
/* 省略其他 */
[GDT_ENTRY_KERNEL_CS] = { { { 0x0000ffff, 0x00cf9a00 } } },
[GDT_ENTRY_KERNEL_DS] = { { { 0x0000ffff, 0x00cf9200 } } },
[GDT_ENTRY_DEFAULT_USER_CS] = { { { 0x0000ffff, 0x00cffa00 } } },
[GDT_ENTRY_DEFAULT_USER_DS] = { { { 0x0000ffff, 0x00cff200 } } },
/*省略其他*/
} };
EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
/*
GDT_ENTRY_KERNEL_CS = 12
GDT_ENTRY_KERNEL_DS = 13
GDT_ENTRY_DEFAULT_USER_CS = 14
GDT_ENTRY_DEFAULT_USER_DS = 15
这里还有一点需要注意
{ 0x0000ffff, 0x00cf9a00 }在内存中应该是0x00cf9a000000ffff
*/
/*include/linux/percpu-defs.h" */
#define DEFINE_PER_CPU_PAGE_ALIGNED(type, name) \
DEFINE_PER_CPU_SECTION(type, name, ".page_aligned")
/*include/linux/percpu-defs.h */
#define DEFINE_PER_CPU_SECTION(type, name, section) \
__attribute__((__section__(PER_CPU_BASE_SECTION section))) \
PER_CPU_ATTRIBUTES PER_CPU_DEF_ATTRIBUTES \
__typeof__(type) per_cpu__##name
|
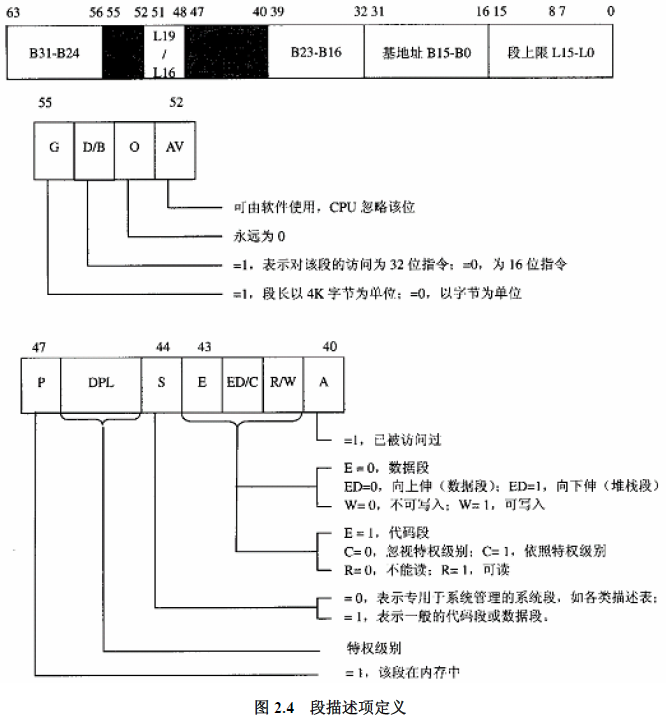
参照gdt表项定义可以得出以下结论
| B31-B24 | | L19-L16 | | B23-B16 | B15-B0 | L15-L0 |
|---|
| __KERNEL_CS | 0x00 | 0xC | 0xF | 0x9A | 0x00 | 0x0000 | 0xFFFF |
| __KERNEL_DS | 0x00 | 0xC | 0xF | 0x92 | 0xFF | 0x00CF | 0xFFFF |
| __USER_CS | 0x00 | 0xC | 0xF | 0xFA | 0xFF | 0x00CF | 0xFFFF |
| __USER_DS | 0x00 | 0xC | 0xF | 0xF2 | 0xFF | 0x00CF | 0xFFFF |
即
- B0-B15, B16-B24 全是0, 段的基地址是0;
- L0-L15, L16-L19 全是1, 段的上限是0xFFFFF;
- G位都是1, 段长单位都为4KB;
- D/B位都为1,对四个段访问的指令都是32位的;
- P位都为1,四个段都在内存中;
- bit40-bit46字段有区别
- __KERNEL_CS : DPL = 0; S = 1代码或数据段;101 代码段,可读;未被访问过;
- __KERNEL_DS : DPL = 0; S = 1代码或数据段;001 数据段,可读,可写;未被访问过;
- __USER_CS : DPL = 3; S = 1代码或数据段;101 代码段,可读;未被访问过;
- __USER_DS : DPL = 3; S = 1代码或数据段;001 数据段,可读,可写;未被访问过;
小结
分段机制中,所有进程公用一个GDT,主要分了四个段:内核代码段、内核数据段、用户代码段、用户数据段,所有进程共享这四个段。这四个段的映射整个内存空间。
页式映射机制
分页机制主要完成虚拟地址(线性地址)到物理地址的映射。
分页机制中,每个进程都有其自己的页目录PGD,指向这个目录的指针保存在每个进程的mm_struct结构中,每当调度一个进程进入运行时,内核都据此设置CR3寄存器,MMU的硬件又从CR3中取得PGD的地址。
CPU给出线性地址0x08048568,写成二进制形式0000 1000 0000 0100 1000 0101 0110 1000。
- 查
PGD: 0000 1000 00十进制为32,以32位为下标,在PGD中找到相应表项,取此表项的高20位后边补12个0组成PT的地址。 - 查
PT : 00 0100 1000 十进制为72,以72位下标,在PT中找到相应的表项,取此表项的高20位后边补12个0,组成页表的地址。 - 查页表:线性地址中省下的12位
0101 0110 1000为地址偏移,上一步查到的页表地址加上此偏移,得到线性地址0x08048568相应的物理地址。
此过程中共访存了3次,第一次取PGD[32],第二次取PT[72],第三次取PT[72]+0101 0110 1000得到物理地址。
时间优化: 快表 TLB;
空间优化: 多级页表。
内核启动过程和启动完成后gdt有所不同,以下为内核启动时gdt的初始化函数调用过程。
参考这篇文章
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| arch/x86/boot/main.c -> main()
-> arch/x86/boot/pm.c : go_to_protected_mode()
-> arch/x86/boot/pm.c : setup_gdt();
static void setup_gdt(void)
{
/* There are machines which are known to not boot with the GDT
being 8-byte unaligned. Intel recommends 16 byte alignment. */
static const u64 boot_gdt[] __attribute__((aligned(16))) = {
/* CS: code, read/execute, 4 GB, base 0 */
[GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff),
/* DS: data, read/write, 4 GB, base 0 */
[GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff),
/* TSS: 32-bit tss, 104 bytes, base 4096 */
/* We only have a TSS here to keep Intel VT happy;
we don't actually use it for anything. */
[GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103),
};
/* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead
of the gdt_ptr contents. Thus, make it static so it will
stay in memory, at least long enough that we switch to the
proper kernel GDT. */
static struct gdt_ptr gdt;
gdt.len = sizeof(boot_gdt)-1;
gdt.ptr = (u32)&boot_gdt + (ds() << 4);
asm volatile("lgdtl %0" : : "m" (gdt));
}
#define GDT_ENTRY_BOOT_CS 2
#define GDT_ENTRY_BOOT_DS (GDT_ENTRY_BOOT_CS + 1)
|
几个重要的数据结构
系统中的每个物理页面都有一个page结构,系统在初始化时根据系统中物理内存的大小建立起一个page结构数组,作为物理页面的“仓库”,里面每个page数据结构都代表系统中一个物理页面。
“仓库”中的物理页面被划分为ZONE_DMA 、 ZONE_NORMAL和ZONE_HIGHMEM区,其中ZONE_HIGHMEM用于物理地址超过1G的存储空间,在64位系统中该区为空。一个管理区用一个zone_struct结构表示。
对于NUMA结构,管理区不再是最高层级的存储管理机构,而是在每个存储节点中都至少有两个管理区,而且前述page结构数组,也不再是全局性的,而是从属于具体的节点。 pg_data_t结构保存节点信息。
pgd_t / pmd_t / pte_t
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| /* arch/x86/include/asm/pgtable_types.h" */
typedef struct { pgdval_t pgd; } pgd_t;
#if PAGETABLE_LEVELS > 2
typedef struct { pmdval_t pmd; } pmd_t; /* 这里为了简单只看 */
#esle
typedef struct { pud_t pud; } pmd_t; //include/asm-generic/pgtable-nopmd.h
#endif
/* arch/x86/include/asm/pgtable-2level_types.h */
typedef unsigned long pteval_t;
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef unsigned long pgprotval_t;
typedef union {
pteval_t pte;
pteval_t pte_low;
} pte_t;
|
页面目录PGD 中间目录PMD 页表PT 分别是由表项pgd_t pmd_t pte_t组成的数组。
1
2
| /* arch/x86/include/asm/pgtable_types.h */
typedef struct pgprot { pgprotval_t pgprot; } pgprot_t; //页面保护的结构
|
struct page
内核中有一个全局量mem_map(定义在mm/memory.c的70行struct page *mem_map;)是一个指针,指向一个page数据结构的数组,每个page代表着一个物理页面,整个数组就代表着系统中的全部物理页面。系统在初始化时根据物理内存的大小建立mem_map。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| /* include/linux/mm_types.h +40 */
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*/
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
atomic_t _count; /* Usage count, see below. */
union {
atomic_t _mapcount; /* Count of ptes mapped in mms,
* to show when page is mapped
* & limit reverse map searches.
*/
struct { /* SLUB */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* SLUB: Pointer to slab */
struct page *first_page; /* Compound tail pages */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
*/
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif
};
|
如果把物理内存看做一个物理页面的“数组”,高20位就是数组的下标,也就是物理页面的序号,用这个下标,可以在上述page结构数组中找到代表目标物理页面的数据结构,实现如下边代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| /* arch/x86/include/asm/pgtable.h */
#define pte_page(pte) pfn_to_page(pte_pfn(pte))
130 static inline unsigned long pte_pfn(pte_t pte)
131 {
132 return (pte_val(pte) & PTE_PFN_MASK) >> PAGE_SHIFT;
/*
176 /* PTE_PFN_MASK extracts the PFN from a (pte|pmd|pud|pgd)val_t */
177 #define PTE_PFN_MASK ((pteval_t)PHYSICAL_PAGE_MASK)
*/
133 }
/*include/asm-generic/memory_model.h*/
70 #define pfn_to_page __pfn_to_page
30 #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
8 #ifndef ARCH_PFN_OFFSET
9 #define ARCH_PFN_OFFSET (0UL)
10 #endif
/*
即
pte_page(pte) 展开为 (mem_map + ((pte) - 0))
其中pte = (pte_val(pte) & PTE_PFN_MASK) >> PAGE_SHIFT
*/
|
struct zone
关于zone的划分,内核中的注释应该能够帮助理解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
__MAX_NR_ZONES
};
|
zone结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| /* "include/linux/mmzone.h" */
struct zone {
/* Fields commonly accessed by the page allocator */
unsigned long pages_min, pages_low, pages_high;
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/
unsigned long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
struct per_cpu_pageset *pageset[NR_CPUS];
#else
struct per_cpu_pageset pageset[NR_CPUS];
/*
* free areas of different sizes
*/
spinlock_t lock;
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
struct free_area free_area[MAX_ORDER]; /* "空闲区间"队列 */
/* 省略一些元素 */
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat; /* 属于哪个NUMA节点 */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; /* 在page结构数组中的起始页面号 */
/*
* zone_start_pfn, spanned_pages and present_pages are all
* protected by span_seqlock. It is a seqlock because it has
* to be read outside of zone->lock, and it is done in the main
* allocator path. But, it is written quite infrequently.
*
* The lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*/
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
/*
* rarely used fields:
*/
const char *name;
} ____cacheline_internodealigned_in_smp;
|
pg_data_t 或者 struct pglist_data
此结构表示每个NUMA节点的存储信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| /* include/linux/mmzone.h */
/*
* The pg_data_t structure is used in machines with CONFIG_DISCONTIGMEM
* (mostly NUMA machines?) to denote a higher-level memory zone than the
* zone denotes.
*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; /* 节点内的 zone,数组 */
struct zonelist node_zonelists[MAX_ZONELISTS]; /* 分配策略数组 */
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map; /* 指向具体节点内的page数组 */
#ifdef CONFIG_CGROUP_MEM_RES_CTLR
struct page_cgroup *node_page_cgroup;
#endif
#endif
struct bootmem_data *bdata;
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* Nests above zone->lock and zone->size_seqlock.
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;
|
每个zonelist规定了一种分配策略,当当前节点中的物理页面不够时,按zonelist中的顺序,从公共存储或者其他cpu的存储中分配页面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| /*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* If zlcache_ptr is not NULL, then it is just the address of zlcache,
* as explained above. If zlcache_ptr is NULL, there is no zlcache.
* *
* To speed the reading of the zonelist, the zonerefs contain the zone index
* of the entry being read. Helper functions to access information given
* a struct zoneref are
*
* zonelist_zone() - Return the struct zone * for an entry in _zonerefs
* zonelist_zone_idx() - Return the index of the zone for an entry
* zonelist_node_idx() - Return the index of the node for an entry
*/
struct zonelist {
struct zonelist_cache *zlcache_ptr; // NULL or &zlcache
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
#ifdef CONFIG_NUMA
struct zonelist_cache zlcache; // optional ...
#endif
};
/* 其中 */
/*
* This struct contains information about a zone in a zonelist. It is stored
* here to avoid dereferences into large structures and lookups of tables
*/
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
|
之前的几个结构都是用于物理空间管理的,下面是虚拟空间管理的。
虚拟空间的管理是以进程为基础的,每个进程都有各自的虚拟内存空间,所有进程的内核空间是共享的。
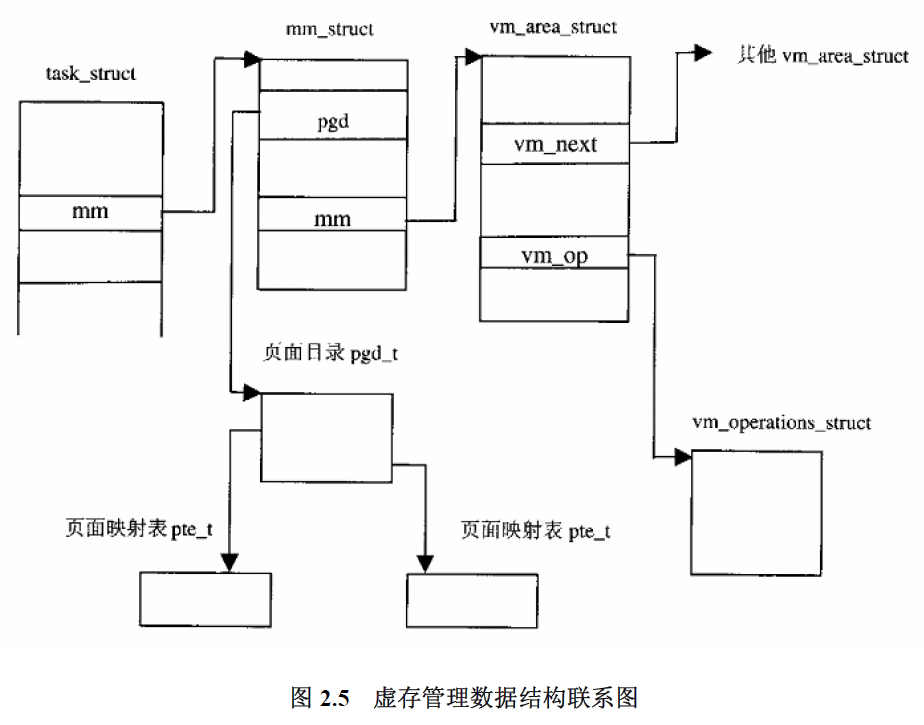
struct vm_area_struct
一个进程所需要使用的虚拟空间中的各个部位未必连续,通常形成若干离散的虚存区间,对虚存区间的抽象就是数据结构struct vm_area_struct.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| /* include/linux/mm_types.h */
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
struct mm_struct * vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
struct rb_node vm_rb;
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
struct vm_operations_struct * vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
|
vm_mm : 指向一个mm_struct结构,是比vm_area_struct更高层次的结构,隶属于task_struct。vm_start和vm_end : 决定了虚存区间,前闭后开即start在区间内,end不包含在区间内;vm_next : 隶属于同一个进程的所有区间的结构链表指针;vm_page_prot 和vm_flags : 表示同一个区间所有页面相同的访问权限以及其他一些属性;vm_rb : 红黑树节点,当区间数量较大时只通过vm_next链式搜索速度太慢,加速搜索;vm_ops : 指向一个vm_operations_struct指针,此结构中保存了一些函数指针,用于操作此区间,比如打开,关闭,建立映射以及处理缺页异常等操作。- 在两种情况下虚存页面(或区间)会和磁盘文件发生联系,
mapping vm_file等几个结构保存这种联系。- swap,内存页面不够分配时,将一些久未使用的页面交换到磁盘上去;
- 通过
mmap()将一个磁盘文件映射到进程的用户空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| /*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* notification that a previously read-only page is about to become
* writable, if an error is returned it will cause a SIGBUS */
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf);
/* called by access_process_vm when get_user_pages() fails, typically
* for use by special VMAs that can switch between memory and hardware
*/
int (*access)(struct vm_area_struct *vma, unsigned long addr,
void *buf, int len, int write);
#ifdef CONFIG_NUMA
/*
* set_policy() op must add a reference to any non-NULL @new mempolicy
* to hold the policy upon return. Caller should pass NULL @new to
* remove a policy and fall back to surrounding context--i.e. do not
* install a MPOL_DEFAULT policy, nor the task or system default
* mempolicy.
*/
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
/*
* get_policy() op must add reference [mpol_get()] to any policy at
* (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure
* in mm/mempolicy.c will do this automatically.
* get_policy() must NOT add a ref if the policy at (vma,addr) is not
* marked as MPOL_SHARED. vma policies are protected by the mmap_sem.
* If no [shared/vma] mempolicy exists at the addr, get_policy() op
* must return NULL--i.e., do not "fallback" to task or system default
* policy.
*/
struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
unsigned long addr);
int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
const nodemask_t *to, unsigned long flags);
#endif
};
|
struct mm_struct
每个进程只有一个mm_struct结构,mm_struct是进程整个用户空间的抽象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
| /* "include/linux/mm_types.h" */
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct rw_semaphore mmap_sem;
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
/* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
/* aio bits */
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
};
|
* mmap : 用来建立一个虚存区间vm_area_struct的单链线性队列;mm_rb : 用来建立vm_area_struct的红黑树结构;* mmap_cache : 用来指向最近一次用到的vm_area_struct结构;* pgd : 指向该进程的页表目录,当内核调度一个进程进入运行时,就将这个地址转换成物理地址,并写入CR3寄存器;map_count : 说明此进程有多少个vm_area_struct结构;mm_users和mm_count : atomic_t(原子)类型,一个进程只能有一个mm_struct,但是一个mm_struct可能同时为多个进程服务,此两个变量用以计数。mmap_sem和page_table_lock : 用于此结构的信号量和用于页表的锁,用于进程间的互斥和并发;start_code, end_code, start_data, end_data : 进程的代码段、数据段,此外还有堆栈段等的起点和终点。
内存管理基本框架
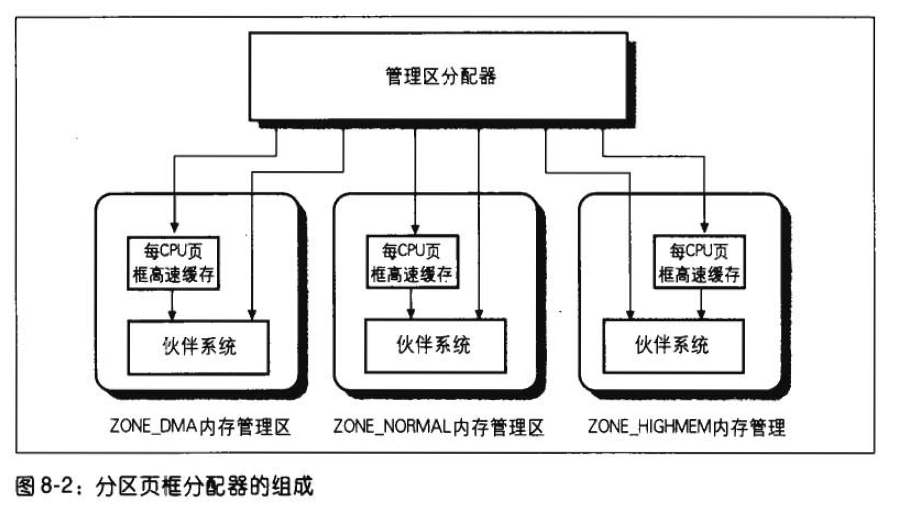
管理区分配器接收动态内存分配与释放的请求,在请求分配的情况下,该部分搜索一个能满足所请求的一组连续的页框的内存管理区。在每个管理区内,页框被伙伴算法系统处理。每CPU页框高速缓存包含一些预先分配,它们被用于满足本地CPU发出的单一内存请求。
伙伴系统
网上超了一段算法的简单描述如下。
为了便于页面的维护,将多个页面组成内存块,每个内存块都有 2 的方幂个页,方幂的指数被称为阶 order。order相同的内存块被组织到一个空闲链表中。伙伴系统基于2的方幂来申请释放内存页。
当申请内存页时,伙伴系统首先检查与申请大小相同的内存块链表中,检看是否有空闲页,如果有就将其分配出去,并将其从链表中删除,否则就检查上一级,即大小为申请大小的2倍的内存块空闲链表,如果该链表有空闲内存,就将其分配出去,同时将剩余的一部分(即未分配出去的一半)加入到下一级空闲链表中;如果这一级仍没有空闲内存;就检查它的上一级,依次类推,直到分配成功或者彻底失败,在成功时还要按照伙伴系统的要求,将未分配的内存块进行划分并加入到相应的空闲内存块链表
在释放内存页时,会检查其伙伴是否也是空闲的,如果是就将它和它的伙伴合并为更大的空闲内存块,该检查会递归进行,直到发现伙伴正在被使用或者已经合并成了最大的内存块。
在linux中可以通过命令cat /proc/buddyinfo查看系统中伙伴系统使用情况。

此处以DMA区域进行分析,第二列值为4,表示当前系统中DMA区域,可用的连续两页的内存大小为4*2*PAGE_SIZE;第三列值为21,表示当前系统中DMA区域,可用的连续四页的内存大小为21*2^2*PAGE_SIZE。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| /* include/mm/mmzone.h */
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))
struct zone {
/* 略 */
struct free_area free_area[MAX_ORDER];
/* 略 */
};
#define MIGRATE_UNMOVABLE 0
#define MIGRATE_RECLAIMABLE 1
#define MIGRATE_MOVABLE 2
#define MIGRATE_RESERVE 3
#define MIGRATE_ISOLATE 4 /* can't allocate from here */
#define MIGRATE_TYPES 5
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
|
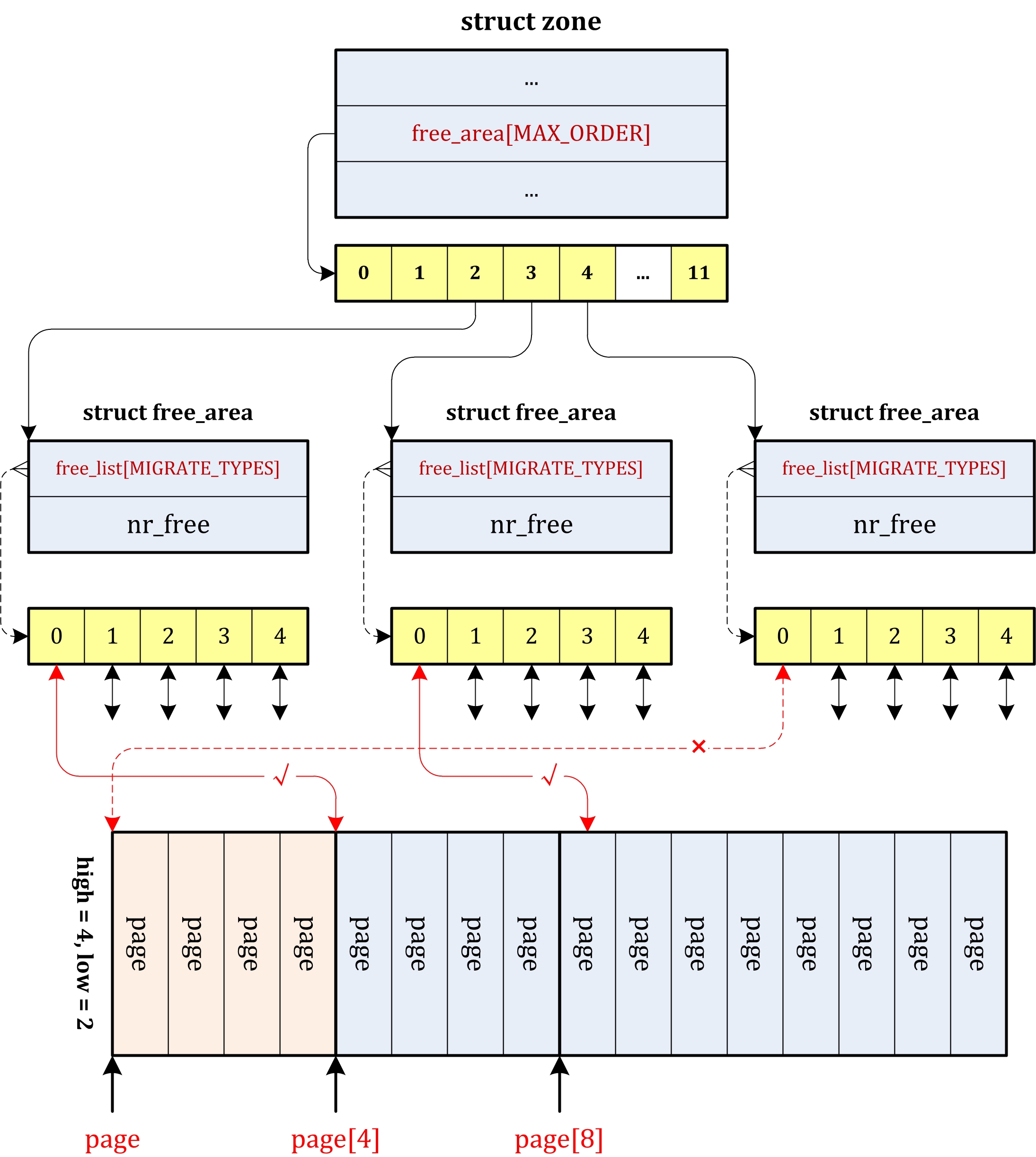
nr_free:其中nr_free表示内存页块的数目,对于0阶的表示以1页为单位计算,对于1阶的以2页为单位计算,n阶的以2的n次方为单位计算。free_list:用于将具有该大小的内存页块连接起来。由于内存页块表示的是连续的物理页,因而对于加入到链表中的每个内存页块来说,只需要将内存页块中的第一个页加入该链表即可。因此这些链表连接的是每个内存页块中第一个内存页,使用了struct page中的struct list_head lru成员。free_list数组元素的每一个对应一种属性的类型,可用于不同的目地,但是它们的大小和组织方式相同。
每个struct zone都有11(MAX_ORDER)个struct free_area结构,每一个free_area包含5(MIGRATE_TYPES)个链表,其中每一个链表中的内存页面按照其自身是否可以释放或者迁移被归为一类,于是凡是请求“不可迁移”页面的分配请求全部在free_list[MIGRATE_UNMOVABLE]这条链表上分配。
1
2
3
4
5
6
| /* include/linux/mm_types.h */
struct page{
/* 略 */
struct list_head lru;
/* 略 */
};
|
参考
Linux /proc/buddyinfo理解
linux 2.6.36的free_area结构
linux内核对伙伴系统的改进–migrate_type
linux内核内存管理学习之二(物理内存管理–伙伴系统)
slab系统
伙伴算法系统采用页框作为基本内存区,这适合于对大块内存的请求,但是如何处理小内存的请求,比如说几十或者几百个字节?linux kernel采用slab系统进行高效的小内存管理。
make menuconfig后输入/搜索slab后回车,会看到下图的路径。
此外还有
- SLAB是基础,是最早从Sun OS那引进的;
- SLUB是在Slab上进行的改进,在大型机上表现出色,据说还被IA-64作为默认;
- SLOB是针对小型系统设计的,主要是嵌入式。
slab分配器把对象分组放进高速缓存,每个高速缓存都是同种类型对象的“储备”。例如,当一个文件被打开时,存放相应“打开文件”对象所需的内存区是从一个叫做filp的slab分配器的高速缓存中得到的。
1
| cat /proc/slabinfo #查看系统中slab使用情况
|
也可以使用slabtop命令查看slab系统使用情况。
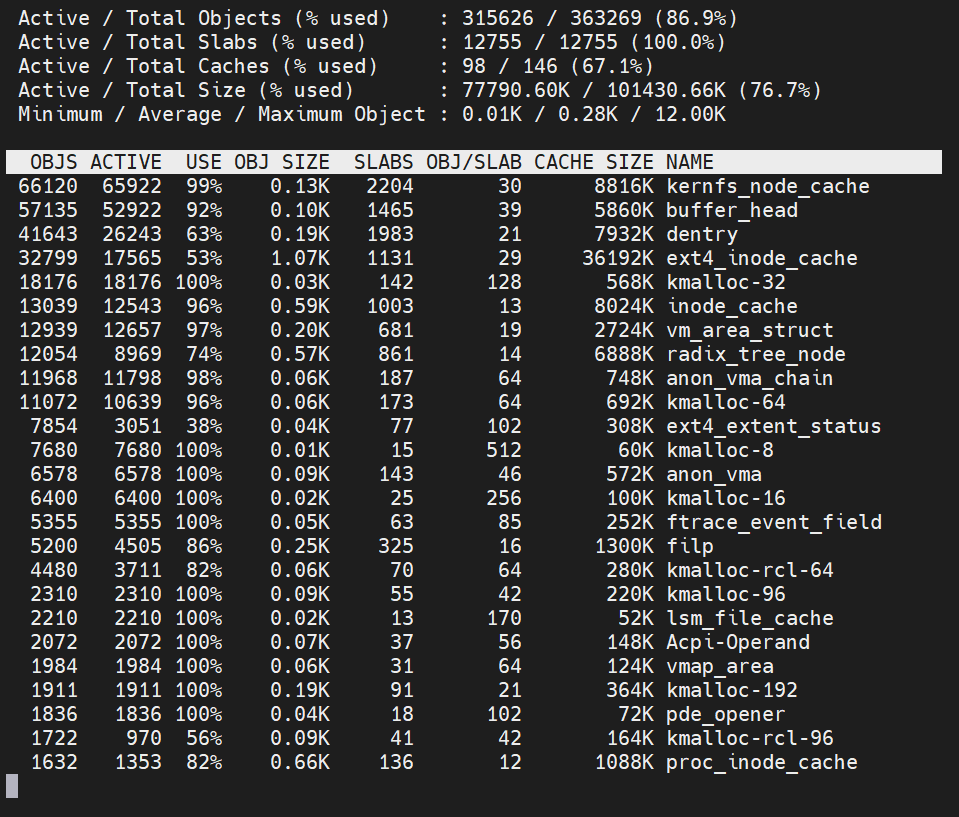
- OBJS — The total number of objects (memory blocks), including those in use (allocated), and some spares not in use.
- ACTIVE — The number of objects (memory blocks) that are in use (allocated).
- USE — Percentage of total objects that are active. ((ACTIVE/OBJS)(100))
- OBJ SIZE — The size of the objects.
- SLABS — The total number of slabs.
- OBJ/SLAB — The number of objects that fit into a slab.
- CACHE SIZE — The cache size of the slab.
- NAME — The name of the slab.
包含高速缓存的主内存区域被划分为多个slab,每个slab由一个或多个连续的页框组成,这些页框中既包含已经分配的对象,也包含空闲的对象。
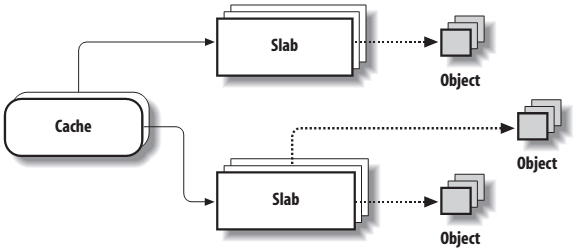
每个高速缓存都是由struct kmem_cache类型的数据结构来描述的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
| /* mm/slab.c */
/*
* struct kmem_cache
*
* manages a cache.
*/
struct kmem_cache {
/* 1) per-cpu data, touched during every alloc/free */
struct array_cache *array[NR_CPUS];
/* 2) Cache tunables. Protected by cache_chain_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int buffer_size;
u32 reciprocal_buffer_size;
/* 3) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 4) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t gfpflags; /* 分配页框时传递给伙伴系统函数的一组标志 */
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *slabp_cache;
unsigned int slab_size; /* 单个slab的大小 */
unsigned int dflags; /* dynamic flags */
/* constructor func */
void (*ctor)(void *obj);
/* 5) cache creation/removal */
const char *name; /* 存放高速缓存的名字 */
struct list_head next; /* 高速缓存描述符双向链表使用的指针 */
/* 6) statistics */
#if STATS
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
#endif
#if DEBUG
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. buffer_size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
int obj_size;
#endif
/*
* We put nodelists[] at the end of kmem_cache, because we want to size
* this array to nr_node_ids slots instead of MAX_NUMNODES
* (see kmem_cache_init())
* We still use [MAX_NUMNODES] and not [1] or [0] because cache_cache
* is statically defined, so we reserve the max number of nodes.
*/
struct kmem_list3 *nodelists[MAX_NUMNODES];
/*
* Do not add fields after nodelists[]
*/
};
|
第一个元素是 struct array_cache,其定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
| struct array_cache {
unsigned int avail; /* 可用对象数目 */
unsigned int limit; /* 可拥有的最大对象数目,和kmem_cache中一样 */
unsigned int batchcount; /* 同kmem_cache,要转移进本地高速缓存或从本地高速缓存中转移出去的对象的个数 */
unsigned int touched; /* 是否在收缩后被访问过 */
spinlock_t lock;
void *entry[]; /*
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
/* entry是一个伪数组,初始没有任何数据项,之后会增加并保存释放的对象指针 */
};
|
其中kmem_list3结构主要保存了三个slab结构链表,是slab系统的核心,其定义如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| /* mm/slab.c */
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full; /* 不包含空闲对象的slab描述符双向循环链表 */
struct list_head slabs_free; /* 只包含空闲对象的slab描述符双向循环链表 */
unsigned long free_objects; /* 高速缓存中空闲对象的个数 */
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
};
|
slab描述符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| /* mm/slab.c */
/*
* struct slab
*
* Manages the objs in a slab. Placed either at the beginning of mem allocated
* for a slab, or allocated from an general cache.
* Slabs are chained into three list: fully used, partial, fully free slabs.
*/
struct slab {
struct list_head list; /* slab描述符的三个双向循环链表中的一个 */
unsigned long colouroff;/* slab中第一个对象的偏移 */
void *s_mem; /* including colour offset slab中第一个对象的地址 */
unsigned int inuse; /* num of objs active in slab 正在使用的非空闲slab的对象个数*/
kmem_bufctl_t free; /* slab中下一个空闲对象的下标 */
unsigned short nodeid;
};
|
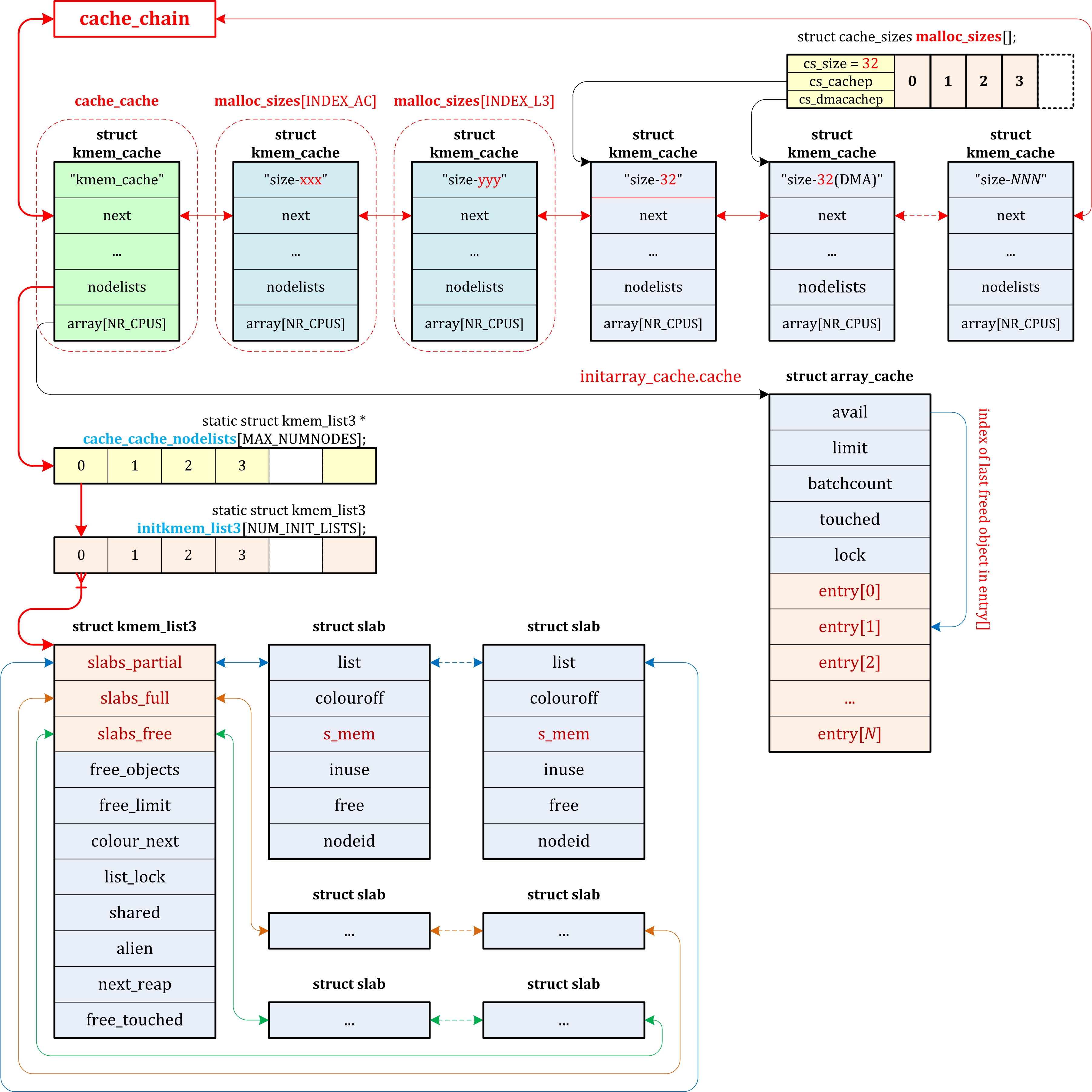
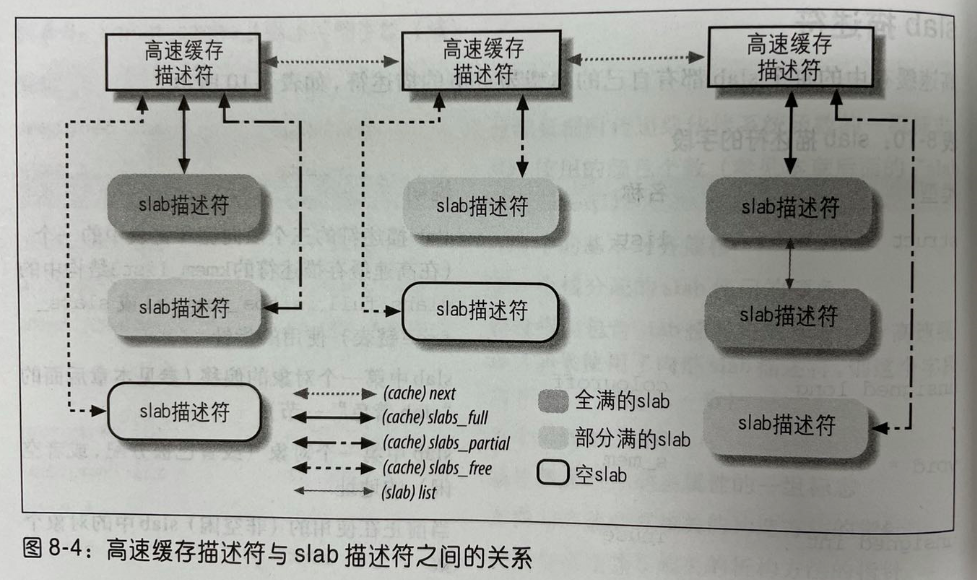
slab分配器的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| /**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo to identify this cache.
* @size: The size of objects to be created in this cache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL on failure.
* Cannot be called within a int, but can be interrupted.
* The @ctor is run when new pages are allocated by the cache.
*
* @name must be valid until the cache is destroyed. This implies that
* the module calling this has to destroy the cache before getting unloaded.
* Note that kmem_cache_name() is not guaranteed to return the same pointer,
* therefore applications must manage it themselves.
*
* The flags are
*
* %SLAB_POISON - Poison the slab with a known test pattern (a5a5a5a5)
* to catch references to uninitialised memory.
*
* %SLAB_RED_ZONE - Insert `Red' zones around the allocated memory to check
* for buffer overruns.
*
* %SLAB_HWCACHE_ALIGN - Align the objects in this cache to a hardware
* cacheline. This can be beneficial if you're counting cycles as closely
* as davem.
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *));
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| /**
* kmem_cache_destroy - delete a cache
* @cachep: the cache to destroy
*
* Remove a &struct kmem_cache object from the slab cache.
*
* It is expected this function will be called by a module when it is
* unloaded. This will remove the cache completely, and avoid a duplicate
* cache being allocated each time a module is loaded and unloaded, if the
* module doesn't have persistent in-kernel storage across loads and unloads.
*
* The cache must be empty before calling this function.
*
* The caller must guarantee that noone will allocate memory from the cache
* during the kmem_cache_destroy().
*/
void kmem_cache_destroy(struct kmem_cache *cachep);
|
1
2
3
4
5
6
7
8
9
| /**
* kmem_cache_alloc - Allocate an object
* @cachep: The cache to allocate from.
* @flags: See kmalloc().
*
* Allocate an object from this cache. The flags are only relevant
* if the cache has no available objects.
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
|
1
2
3
4
5
6
7
8
9
| /**
* kmem_cache_free - Deallocate an object
* @cachep: The cache the allocation was from.
* @objp: The previously allocated object.
*
* Free an object which was previously allocated from this
* cache.
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| /* 1. 定义一个全局变量存放指向task_struct高速缓存的指针 */
struct kmem_cache *task_struct_cachep;
/* 2. 内核初始化期间,在kernel/fork.c中的fork_init()中会创建高速缓存 */
/* create a slab on which task_structs can be allocated */
task_struct_cachep = kmem_cache_create("task_struct", sizeof(struct task_struct), ARCH_MIN_TASKALIGN, SLAB_PANIC, NULL);
/* 3. 从task_struct_cachep中分配对象
do_fork() ->
copy_process() ->
dup_task_struct() ->
struct task_struct *tsk;
tsk = alloc_task_struct();
其中alloc_task_struct() 定义为
*/
#ifndef __HAVE_ARCH_TASK_STRUCT_ALLOCATOR
# define alloc_task_struct() kmem_cache_alloc(task_struct_cachep, GFP_KERNEL)
# define free_task_struct(tsk) kmem_cache_free(task_struct_cachep, (tsk))
static struct kmem_cache *task_struct_cachep;
#endif
/* 即 */
struct task_struct *tsk;
tsk = kmem_cache_alloc(task_struct_cachep, GFP_KERNEL);
|
slab系统申请页框
当slab分配器创建新的slab时,它依靠分区页框分配器来获得一组连续的空闲页框(一般是从伙伴系统获得)。一般调用kmem_gerpages()函数实现。
给高速缓存分配slab
只有当 已发出一个分配新对象的请求,且高速缓存不包含任何空闲对象时,才给高速缓存分配slab。
slab分配器通过调用cache_grow()函数给高速缓存分配一个新的slab。cache_grow()调用kmem_getpages()获得一组页框来存放一个单独的slab,然后调用alloc_slabmgmt()函数获得一个新的slab描述符。接着调用cache_init_objs()函数,它将构造方法应用到新的slab包含的所有对象上,最后调用list_add_tail()来讲新得到的slab描述符*slabp,添加到高速缓存描述符*cachep的全空slab链表的末端,并更新告诉缓存中的空闲对象计数器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
| /* mm/slab.c" */
/*
* Grow (by 1) the number of slabs within a cache. This is called by
* kmem_cache_alloc() when there are no active objs left in a cache.
*/
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
struct slab *slabp;
size_t offset;
gfp_t local_flags;
struct kmem_list3 *l3;
/*
* Be lazy and only check for valid flags here, keeping it out of the
* critical path in kmem_cache_alloc().
*/
BUG_ON(flags & GFP_SLAB_BUG_MASK);
local_flags = flags & (GFP_CONSTRAINT_MASK|GFP_RECLAIM_MASK);
/* Take the l3 list lock to change the colour_next on this node */
check_irq_off();
l3 = cachep->nodelists[nodeid];
spin_lock(&l3->list_lock);
/* Get colour for the slab, and cal the next value. */
offset = l3->colour_next;
l3->colour_next++;
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
spin_unlock(&l3->list_lock);
offset *= cachep->colour_off;
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/*
* Get mem for the objs. Attempt to allocate a physical page from
* 'nodeid'.
*/
if (!objp)
objp = kmem_getpages(cachep, local_flags, nodeid);
if (!objp)
goto failed;
/* Get slab management. */
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
if (!slabp)
goto opps1;
slab_map_pages(cachep, slabp, objp);
cache_init_objs(cachep, slabp);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&l3->list_lock);
/* Make slab active. */
list_add_tail(&slabp->list, &(l3->slabs_free));
STATS_INC_GROWN(cachep);
l3->free_objects += cachep->num;
spin_unlock(&l3->list_lock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}
/*
简单总结cache_grow()的流程
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
objp = kmem_getpages(cachep, local_flags, nodeid); //获得页框
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid); //获得一个新的slab描述符
cache_init_objs(cachep, slabp); // 初始化slab
list_add_tail(&slabp->list, &(l3->slabs_free)); //将新分配的slab加入到空闲链表
l3->free_objects += cachep->num; //更新空闲slab计数器
}
*/
|
关于高端内存
全文参考
大佬的blog
ULK3
LKD3
Linux内核源代码情景分析