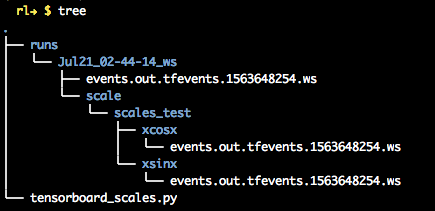
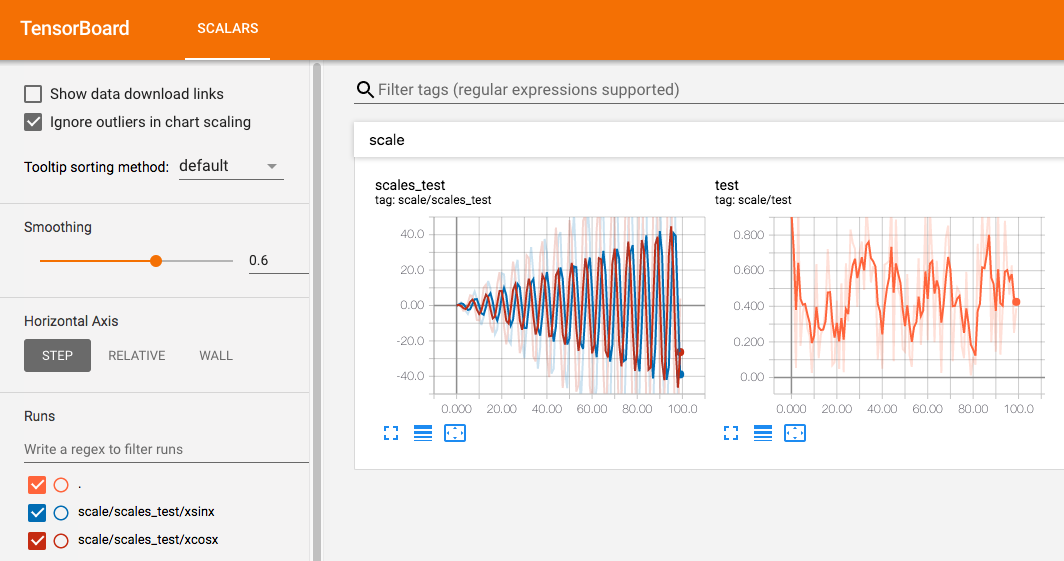
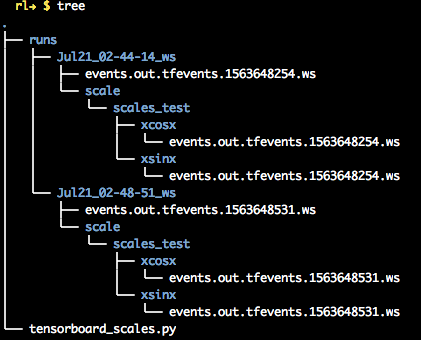
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
max_steps = 1000 # 最大迭代次数
learning_rate = 0.001 # 学习率
dropout = 0.9 # dropout时随机保留神经元的比例
data_dir = './' # 样本数据存储的路径
log_dir = './' # 输出日志保存的路径
mnist = input_data.read_data_sets(data_dir, one_hot=True)
sess = tf.InteractiveSession()
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
def weight_variable(shape):
"""Create a weight variable with appropriate initialization."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
"""Create a bias variable with appropriate initialization."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# 设置命名空间
with tf.name_scope(layer_name):
# 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
# 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
# 执行wx+b的线性计算,并且用直方图记录下来
with tf.name_scope('linear_compute'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('linear', preactivate)
# 将线性输出经过激励函数,并将输出也用直方图记录下来
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
# 返回激励层的最终输出
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('loss'):
# 计算交叉熵损失(每个样本都会有一个损失)
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope('total'):
# 计算所有样本交叉熵损失的均值
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('loss', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(
cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# summaries合并
merged = tf.summary.merge_all()
# 写到指定的磁盘路径中
train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(log_dir + '/test')
# 运行初始化所有变量
tf.global_variables_initializer().run()
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}
for i in range(max_steps):
if i % 10 == 0: # 记录测试集的summary与accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # 记录训练集的summary
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()
|